Výběrová statistická šetření
Nejdůležitějším druhem neúplného šetření je pravděpodobnostní
neboli náhodný výběr. Provádí se tak, že se celý soubor nejprve rozdělí na výběrové
jednotky – které jsou zpravidla totožné s elementárními
(statistickými) jednotkami, ale mohou to být také jejich větší nebo menší
skupiny – načež se každé výběrové jednotce přiřadí určitá
(nejčastěji stejná) pravděpodobnost jejího zahrnutí do výběrového
souboru. Vlastní výběr (selekce) jednotek se pak provede tak, aby o vybrání
či nevybrání každé jednotky rozhodovala již jen náhoda. (Prakticky se dá
takový výběr uskutečnit třeba tak, že se jednotky nebo lístky s názvy
jednotek vylosují z osudí. K této technické stránce problému se ještě vrátíme.)
Obě zmíněné stránky tvorby výběrového souboru –
pravděpodobnost a náhodu – je třeba vidět v jejich spojitosti. Uplatnění
předem stanovených pravděpodobností vyžaduje naprostou náhodnost při
vlastním vybírání, a naopak náhodnost předpokládá existenci určité
soustavy pravděpodobností. Pro výraznější rozlišení obou stránek budeme
mluvit o pravděpodobnosti vybrání
(vytažení) – později o příbuzném pojmu pravděpodobnosti zahrnutí –
jakožto vlastnostech jednotky a o náhodnosti vybírání
jako metodě výběru.
Pravděpodobnostní hledisko náhodného výběru je
natolik významné, že v současnosti již název "pravděpodobnostní
výběr" převažuje nad starším a v praxi dosud občas užívaným názvem
"náhodný (přesněji náhodový)
výběr". Určitý význam má v tomto i ta okolnost, že pravděpodobnosti
vybrání nemusí být v daném souboru u všech jednotek stejné, ale mohou se
lišit. V souvislosti s tím je třeba upozornit, že v některé
poválečné české (ale i cizojazyčné) literatuře byl termín "pravděpodobnostní
výběr" vyhrazen pouze pro výběry s nestejnými pravděpodobnostmi.
U neodborníků se může statistik často setkat s
pochybnostmi, jak je možné, že náhodný výběr může být dobrým
podkladem pro zabezpečení reprezentativnosti, a tím pro usuzování z části
na celek. Zdá se jim, že pokud ponecháme náhodě, které prvky budou vybrány,
přestáváme řídit a ovlivňovat tvorbu výběrového souboru, stáváme se
"obětí živelnosti" atd. To by ovšem platilo, kdyby se výběr prvků
prováděl s různými a nám neznámými pravděpodobnostmi. Avšak tím, že
všem prvkům přiřadíme předem známé
pravděpodobnosti – a to buď pravděpodobnosti vybrání nebo pravděpodobnosti
zahrnutí – můžeme využít výhodných stránek náhody, matematicky
ovládat její zákonitosti.
V porovnání s úsudkovými (záměrnými) výběry to tedy znamená, že
u pravděpodobnostních výběrů jsme schopni sestavit takové odhady, které s rostoucím rozsahem výběru konvergují k odhadované
(skutečné) hodnotě – tzv. odhady konzistentní – a které často navíc
při každém rozsahu výběru skutečnou hodnotu v průměru ani nenadhodnocují,
ani nepodhodnocují – tzv. odhady nevychýlené.
Jejich přesnost lze při daném rozsahu výběru
objektivně změřit, tj. určit střední velikost jejich výběrové chyby,
popř. stanovit interval, v němž se téměř jistě nachází skutečná
hodnota – tzv. intervalové odhady.
Odhady získané z úsudkového výběru nemají naproti
tomu ani jednu z těchto vlastností. Již jsme se zmínili o tom, že možnou
(přípustnou) chybu těchto odhadů může odhadnout
subjektivně pouze znalec, který sestavil výběrový soubor. Rozsah výběru
neovlivňuje u úsudkového výběru střední velikost výběrové chyby buď vůbec,
nebo jen nepatrně. To lze vysvětlit tím, že např. při snaze vybrat záměrně
samé "typické", "průměrné" jednotky bude představa
znalce těchto jednotek stále táž, ať vybírá 5, nebo 50 jednotek. Vzájemný
poměr chyb při obou způsobech vybírání lze znázornit graficky –
viz obr. 1. Graf však znázorňuje vzájemný vztah velikosti chyb schematicky,
ukazuje pouze jeho formu. Vztah není možné změřit číselně (označit na
osách měřítko) zejména proto, že velikost chyby při úsudkovém výběru
se u různých osob liší.

Z porovnání obou výběrů – úsudkového a pravděpodobnostního vyplývá,
že úsudkový výběr je zdánlivě výhodnější, protože se mohou využít
předběžné informace o zkoumaném souboru. Tyto informace lze však využít
i výběrem s nestejnými pravděpodobnostmi nebo pomocí složitějších odhadů. Ke každému způsobu úsudkového
výběru existuje již dnes obdoba pravděpodobnostního výběru, teoreticky
dostatečně propracovaná, že využití předběžné informace je při ní
dokonalejší než při výběru úsudkovém.
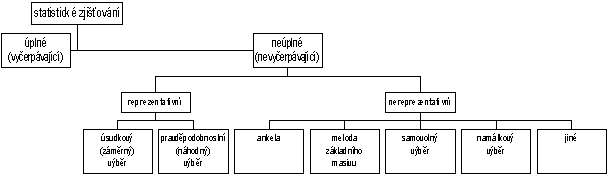
V přehledu hlavních druhů neúplného statistického zjišťování
jsme vynechali ty druhy, které se sice podobají náhodným výběrům, přesto
však je nelze označit jako reprezentativní metodu, tj. nelze získané
poznatky zobecnit na celý soubor. Jsou to především samovolné výběry,
jako např. "výběr" osob, které uzavřely určitou pojistku, nebo
osob, jimž byla na ulici v určitém místě a během určité doby položena nějaká
otázka, nebo osoby, jež navštívily nějaký obchodní dům apod. Za
reprezentativní metodu nelze rovněž považovat např. výběr kusů z hejna
drůbeže, které "namátkou" pochytáme na dvoře apod.
V uvedených případech a v případech jim podobných
rozhodují o vybrání každé výběrové jednotky neznámé zákonitosti, i
když často promísené se značnou dávkou nahodilosti. Kromě toho často ani
nejsme schopni říci, z jakého základního souboru tento "výběr"
pochází. Je proto třeba zobecňování závěrů získaných z takových
"výběrů" odmítnout jako neopodstatněné a tedy nevěrohodné.
Všechny uvedené druhy statistického zjišťování můžeme
přehledně sestavit do schématu znázorněného na obr. 2.
 Obrázek 2
Obrázek 2